Cosmic-Radiance: Just another rate limiting proxy
Cosmic-Radiance. Cosmic-Radiance!? Cosmic-Radiance is more than Tarics ultimate or a perfume released by Britney Spears (I bet you didn't know that). Cosmic-Radiance is the all-in-one rate limiting proxy for your next League of Legends programming project.
It acts as a middleware between your application and the Riot Games API, ensuring that you never exceed the rate limits imposed by Riot. With Cosmic-Radiance, you can focus on building your application without worrying about hitting rate limits and getting blocked. You can use Cosmic-Radiance either as a real proxy server or as a custom HTTP server that you can hit directly from your application.
Additionally, Cosmic-Radiance is fully battle tested with over 2 billion (ongoing) requests served for this years YearIn.LoL iteration.
Features ✨
- Automatic Rate Limiting: Cosmic-Radiance automatically manages your API requests to ensure you stay within Riot's rate limits.
- Automatic Limit Detection: Cosmic-Radiance can automatically detect and adjust to the rate limits based on your Riot API key.
- Prioritization: You can assign different priority levels to your requests, ensuring that critical requests are processed first.
- Customizable Timeout and good Retry-After handling: You decide how long requests can take and Cosmic-Radiance will handle 429 responses gracefully.
- GZIP-Handling: Cosmic-Radiance supports GZIP compression to optimize data transfer and reduce bandwidth usage.
- Prometheus Integration: Easily monitor your request metrics with built-in Prometheus support.
- Easy to Use: Simple configuration and setup to get you started quickly.
- Open Source: My code sucks? No worries, it's open source. Feel free to fix it yourself or open up an issue on GitHub.
- Up to 99% close to uptime rate limit utilization: Cosmic-Radiance is designed to maximize your API usage without actually hitting or exceeding the limits.
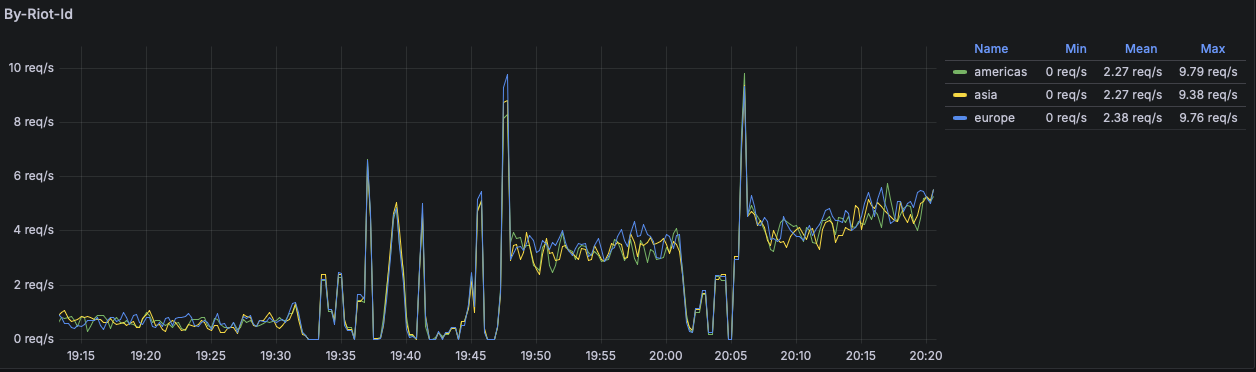 A quick look at the Prometheus metrics Cosmic-Radiance exposes (here: account-v1/by-riot-id).
A quick look at the Prometheus metrics Cosmic-Radiance exposes (here: account-v1/by-riot-id).
A quick sidenote: This part was not written by AI, I just really like the sparkle emoji.
Why another rate limiter?
There are already plenty of rate limiting libraries and proxies out there, so why did I decide to create Cosmic-Radiance?
YearIn.LoL is a massive project that requires making a lot of requests to the Riot Games API. The rate limiting library we used prior to Cosmic-Radiance weren't able to handle the scale, speed and precision of our needs. We needed to write our own solution. I don't like writing code solely for my own project, so I decided to make it open source and share it with everyone interested.
Choosing the programming language was quite complicated. The old library was written in Python and used way too much RAM for our liking. Most of the other popular alternatives were written in similar high-level languages, like JavaScript (TypeScript) or had an approach, that didn't fit our needs. I wanted something lightweight, fast and efficient. After evaluating multiple options, I settled on Go due to its performance, the ability to use pointers and its strong concurrency support. Later I found out, that the strong concurreny support wasn't even needed as Cosmic-Radiance became single-threaded, but hey, at least I learned something new! Hater would say that I should have used Rust, but I wasn't fluid enough in it back then and the clock was ticking.
And why a rate limiting proxy? It would be way more efficient if we built in the rate limiting logic directly into our application, right? Yes, however a proxy can not just be a drop-in-replacement and work with other libraries as well, it also means that you have one central instance which keeps track of all requests and their limits. This way, you can easily scale your application horizontally without worrying about each instance managing its own rate limits. Additionally, a proxy can be monitored and managed separately from your application, making it easier to debug and optimize.
Another quick sidenote: Unlike this article, Cosmic-Radiance was written in late August 2025. The concept of writing a rate limiter was almost a year older though.
Structure
Cosmic-Radiance essentially consists of two main components: the (incoming) request handler and the rate limiter.
The request handler is responsible for receiving incoming requests from your application, enqueing them in a queue and processing them one by one. It also handles the responses from the Riot Games API and forwards them back to your application.
The rate limiter runs in a single thread to ensure atomicity and is responsible for managing the rate limits imposed by Riot. It keeps track of the number of requests made, the time window for those requests, and ensures that requests are only sent when they are within the allowed limits. If a request exceeds the limit, it is delayed until it can be sent without exceeding the limit. The rate limiter also notifies the request handler when a request can be sent. The request handler then reports back if the current request did not came out as expected (e.g. 429 response) and the rate limiter adjusts accordingly.
Additionally, the rate limiter can automatically detect the rate limits based on the rate limits your key has. By default, all known Riot API endpoints and their limits are set to 5 requests per second - in my opinion a good middle ground. When the first request to a specific endpoint is made, Cosmic-Radiance will adjust the limits for that endpoint based on the response headers received from Riot. Cosmic-Radiance can keep track of endpoints and regions separately, allowing for more granular rate limiting.
Request Scheduling
Riot Games uses the fixed window rate limiting algorithm. It is almost impossible to know in which time window your requests are being counted - especially with network delay.
Cosmic-Radiance tracks these windows internally as well to create a (hopefully) ideal replica of the limits on Riot Games API. By default, Cosmic-Radiance only allows [max rps] * seconds requests per started window. If you enqueue more requests than requests can be processed in that window, your requests over time graph will look linear.
If there are too few requests made in said window and you suddenly enqueue a lot of requests, Cosmic-Radiance will try to fit them into the remaining slots of the current window, until it reaches its linear behavior again. This way, Cosmic-Radiance can achieve up to 99% utilization of the rate limits without actually exceeding them.
Priority requests are a bit different. They ignore the linear behavior and are always processed as soon as possible, even if that means exceeding the ideal utilization. This way, you can ensure that critical requests are always processed first (like account lookups).
Let's take a look at a quick example:
We are using a personal key with normal limits (100 requests in 2 minutes [120 seconds]). That means we have an average of 100 / 120 = 0.8333 requests per second. The following graph shows how 100 normal priority requests are being processed over time:
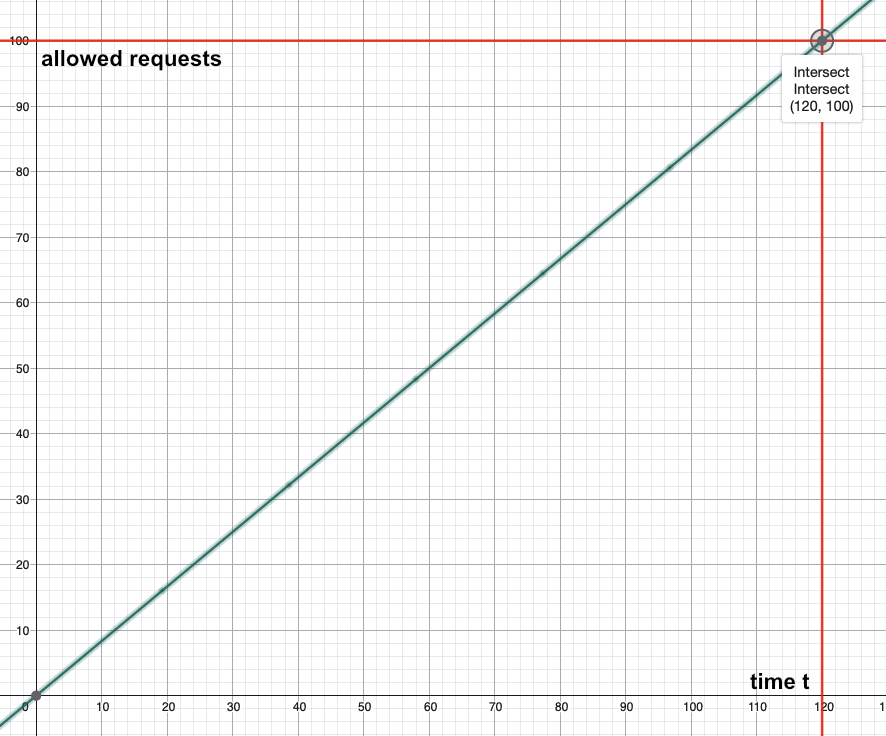
As you can see, the 100th request intersects the 120 seconds mark, meaning that we reached our limit exactly at that point in time. Cosmic-Radiance ensured that we never exceeded the limit, while still utilizing it as much as possible.
The rate limiting component of Cosmic-Radiance checks the limits several times per second for every endpoint and region and notifies the request handler when requests can be processed. This way, the request handler can process requests as soon as possible without waiting for a fixed interval.
Performance
I'd love to say that Cosmic-Radiance is super performant, unfortunately it is just super fast. Based on the check interval of the rate limiter (which can be changed in the settings), Cosmic-Radiance can eat up a lot of CPU time.
Not enough CPU to kill your server, but enough to be noticeable when there are many other processes running. The RAM usage on the other hand is super good, usually not more than 50-100MB depending on your rate limits and maximum queue size.
What is really bottlenecking Cosmic-Radiance is the maximum throughput of your network connection or the most incoming requests per second. In our production environment, we had to spin up one instance of Cosmic-Radiance per region to handle the load. The issue became a lot better when Cosmic-Radiance was deployed directly on the host and not in a containerized environment.
Do we know why the incoming requests were never reaching Comisc-Radiance at all? No. It might be related to Kubernetes networking, the host machine or Docker. From a technical standpoint, Cosmic-Radiance should be able to handle way more requests per second than we ever needed and that was also what the performance metrics were showing us. However, due to the unknown bottleneck, we had to scale horizontally.
What's next?
Cosmic-Radiance might be battle tested and production ready, but there is still a lot of room for improvement. If you have any ideas or free time, feel free to open up an issue or a pull request on GitHub.
Ready to give Cosmic-Radiance a try?
You can find Cosmic-Radiance on GitHub along with the documentation to get you started. It should be pretty straightforward to set up and use. If you have any questions or need help, feel free to open up an issue on GitHub.
Cosmic-Radiance can be deployed via
- Docker (registry)
- Docker (build from source)
- Go (CLI)
- Go (package) - yes you heard that right, you can integrate Cosmic-Radiance directly into your Go application as a package!
Check out all the cool environment variables to fine tune your own instance to your own needs.
The last sidenote: If you have normal rate limits, Cosmic-Radiance is probably overkill for your project (feel free to give it a try though). However, if you are working on a big project with high request volumes, Cosmic-Radiance might be just what you need. Cosmic-Radiance runs under the Apache 2.0 license which means it can be used or modified in commercial environments (with attribution).